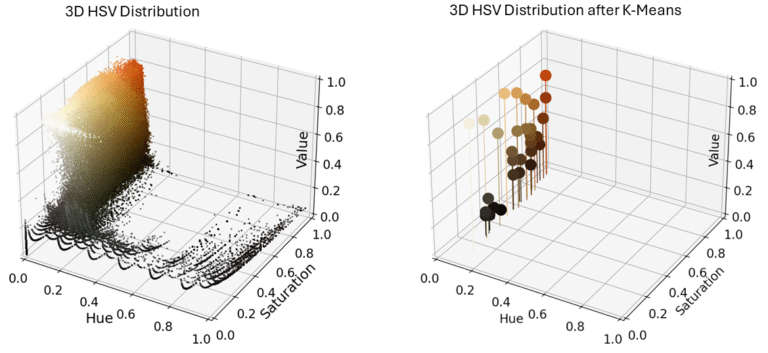
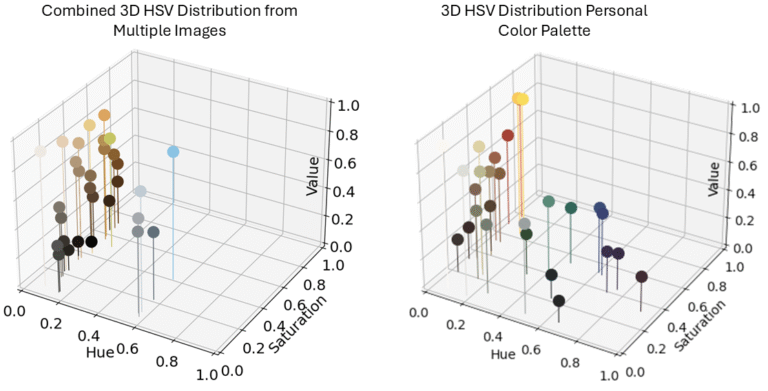
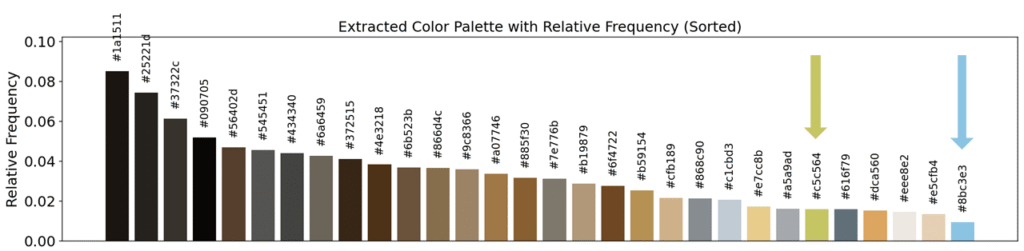
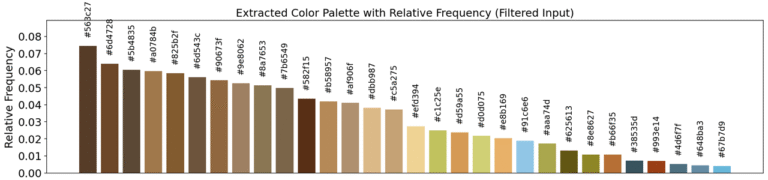
To get an idea of the colors Rembrandt used (and this is by no means true, but rather an approximation from my beginner model), we use the same technique as in my previous post, namely, K-Means Clustering.
This algorithm starts by randomly placing k cluster centers. Then, for each pixel, it determines which cluster center it is closest to and assigns the pixel to that cluster. Once all pixels are assigned, the cluster centers are updated to be the average of the points assigned to them. This process repeats until the cluster centers stabilize.
Even though K-Means doesn’t explicitly track how often a color occurs, it implicitly accounts for color frequency because it processes every pixel in the image. If a particular color appears often, there will be many data points close to it, which pulls a cluster center toward that color during averaging. As a result, frequent colors have more influence on the final cluster centers than rare ones.
For this experiment, I chose to use 30 clusters, which roughly corresponds to the number of paint colors I have available. The resulting clusters are shown in Figure 2 (right), and as expected, they all fall within the red-orange hue range. Using these 30 representative colors, I then recolored the original painting by replacing each pixel with the color of its assigned cluster. The result is shown in the Figure below, where a slider allows you to compare the original image (left) with the recolored version (right).